Converting Data to Vectors
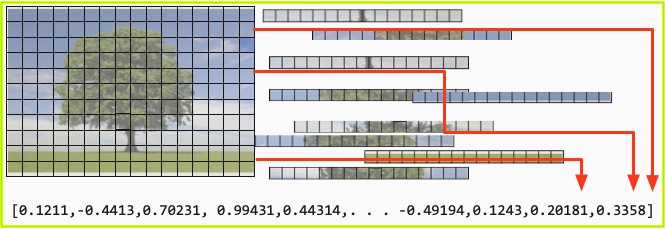
- Above: an image, in this case a tree, is placed on a grid of dimensions R X D.
- The red-green-blue video value of each square on the grid is converted to a real value.
- These values are stremed and converted to a vector who dimensionality is R X D.
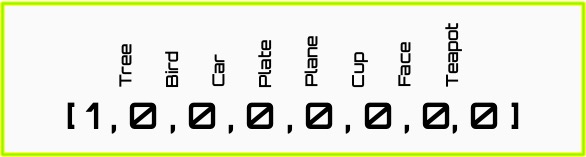
- Below: the output vector has one element for each possible label. The correct label is set to one, the others to zero.
This tool has made civilization possible in two ways: First, language allows the transmission and continuation of knowledge and culture from one generation to the next. Second, like so many of our other tools, it builds and furthers human cognitive development.
Humanity is, as with so many of its tools, at a critical juncture with language. We are increasingly swamped with linguistic data. Our ability to filter and process it is increasingly diminishing. We are drowning in data. Each second, more information is created than one human could absorb in an entire lifetime, and each second the situation only grows worse. Tools to ameliorate this problem have only begun to be developed. Amongst them are a series of loosely coupled techniques lumped under the clunky but at-this-point unavoidable appellation “artificial intelligence.”
Meet Artificial Intelligence
About fifty years ago, dating back at least to the expectations set by the mutinous computer HAL 9000 in the movie 2001: A Space Odyssey, experts began to promise us large and imminent breakthroughs in the field of artificial intelligence (AI). These promissory notes have only recently begun to pay off. One of those major payoffs has come in the area of neural networks or, as it is now more often called, deep learning.
Minsky and Papert’s 1969 book Perceptrons argued that neural networks were too weak to solve any serious and interesting problems in AI. However, perceptrons are one-layer, linear neural networks. They are the simplest type of neural network, and do not have deep, multiple layers and non-linear connections as deep learners do. The many counterarguments that Perceptronsinspired arguably kick-started the modern era of deep learning.
What Is Deep Learning
Some of the biggest returns in AI have come from deep learners: layers of densely connected units processing information and passing it to other layers for further processing. Deep learners have made significant advances in object detection, facial recognition, linguistic analysis and a host of other applications.
A detailed discussion of deep learning and its strengths and weaknesses compared to other AI approaches are beyond the scope of our humble goals here. That is a topic that can, and has, taken up an entire course’s worth of lectures. However, on the unlikely chance that our reader is beginning this while early on a lengthy transcontinental flight, we discuss a few points of deep learning as they relate to our endeavor in this section.
A Minimalist Work-in-Progress
Our guiding philosophy in this endeavor is embodied in the minimalism of The Elements of Style, especially Rule 13: “Omit Needless Words.” This minimalist philosophy was also embodied in Henry Ford's Model A, which only had a windshield wiper on the driver's side.
Finally, we request the reader hold in mind, as they evaluate this writing, that this is an evolving work in progress, with its concomitant possibility for inaccuracies and inconsistencies.
Our development model allows algorithm designers to expose as much or as little of their algorithm as they choose. They can publish a web-service that consumes inputs and provides outputs according to our JSON API specification (minimum exposure), or they can publish full details of their algorithm.
On the front end, we provide a web-based graphical user interface (GUI) that mediates between end users and the algorithms. End users include writers and editors wanting to improve existing content or to generate new content.
The open source nature of the project allows anyone else to provide their own front-end interface to the same algorithms. We have full competition on both sides: algorithmic, and user experience. Rather than measuring a given algorithm by how well it does on a test data set, or series of data sets, in vitro, so to speak, the GUI provides a mechanism for the researcher to actively investigate algorithm performance in vivo, and to iteratively improve it. instantiation of a document is rendered from the base “quantum document” that personal information about the target is possibly required.
Targeting and the technologies behind it are relevant to our current endeavor because an important component of what we want our algorithms to perform is personalization. When we edit existing content and try to improve it with respect to a target or when we generate new conten, if we are personalizing it then we are targeting it. We expect many of the same issues that have come up with targeting in our previous work will come up here as well. Thus many of our discussions of this project will address the targeting aspect as appropriate.
So Much Data
Humanity is faced with a huge amount of data—more every day. We must tame it: search for what we are interested in, transform it into a useful form, and find connections between pieces of content that may be in disparate locations across the web.
We have many algorithms to help us, and new ones are being created every day. Choosing which algorithms to use with which problems and which types of data is, in itself, a big problem.
As of this writing, July 2020, 1.7 Megabytes of data for every person alive are created every second. That includes:
- 2.5 quintillion bytes of data produced by humans every day
- 306.4 billion emails sent every day
- 500 million Tweets broadcast every day
So Many Algorithms
Researchers are producing many deep learning, natural language processing algorithms, as noted above. We can think of these as “naked” algorithms, in the sense that they are generally not developed with a specific end-use application in mind. They do not come pre-packaged as part of a complete application, necessarily. Rather, they may be solutions looking for a problem. These are algorithms produced outside of an ecosystem with which to use them.
Contrast these with the less common fully formed applications that are designed for a particular task. These approaches are more piecemeal and transactional. In that case, what we are working with and testing is not just an algorithm, but an entire system, including the algorithms and all of the ancillary programs and front-end applications that work with them.
We would like to see these two approaches move closer together. Algorithms are only part of the overall ecosystem of content management, evaluation, and generation. By placing naked algorithms within the more ecologically valid context of real-world use we accelerate the development of their utility. However, much of the current state of the art in deep learning NLP algorithms involves testing a new algorithm against some benchmark dataset and showing that it performs better than some other comparable set of algorithms.
Our approach augments this, and may be thought of as a broader, more genetic and more ecologically valid approach to development. It is “genetic” in the sense that we have a variety of algorithms free to be applied in a variety of contexts, and like a genetic algorithm over time we can determine which algorithms work best overall, in a variety of contexts, not just in one test.
Matching algorithm to problem
New algorithms to search, transform, compress and generate data are invented and tested every day. With this huge and ever increasing volume of data, such algorithms are desperately needed. As the search space of possible algorithmic solutions increases, a framework for matching viable algorithms to problems is also needed. The problem is to match algorithms which look good on paper to real-world applications, within a framework that permits us to prove its utility in vivo. We can think of this as an iterative, ongoing bake-off.
Learning vs Programming
All AI (Artificial Intelligence) systems, at a most basic level of explanation, transform input to output. How is this achieved?
We must either teach our system or program it with rules. The first is the inferential, statistical approach used by deep learners, amongst others, and the second is the rule-based approach used by more traditional AI. Some of the problems that deep learners solve can be formally described as categorization problems:
- What is the object in this picture?
- What part-of-speech is this word?
- What magazine brand does this document most likely come from?
- What demographic does this document match to?
Deep learners can also be used to generate data—in our case, to generate new documents. A deep learner is a series of processing elements that finds patterns or regularities in the inputs. Those patterns or regularities then become inputs to the next layer, and so on, in a process similar (though much simplified) to the organization of the brain. At each layer, higher level feature creation and organization occur.
The deep learning system need only be presented with exemplars: examples of input and output pairs. This is one advantage to the learning approach, for the system discovers rules for translating input to output, without having to have a knowledge worker explicitly discover rules and implement them in code.
Long-term experience with these systems tells us that often the “rules” that emerge from such learning algorithms are more nuanced and hence more accurate than the rules that humans come up with when trying to describe accurate maps from input to output. This is another benefit of the deep learning approach, compared to explict rule-based approaches.
Figure A shows a simplified example of how a deep learner architecture.
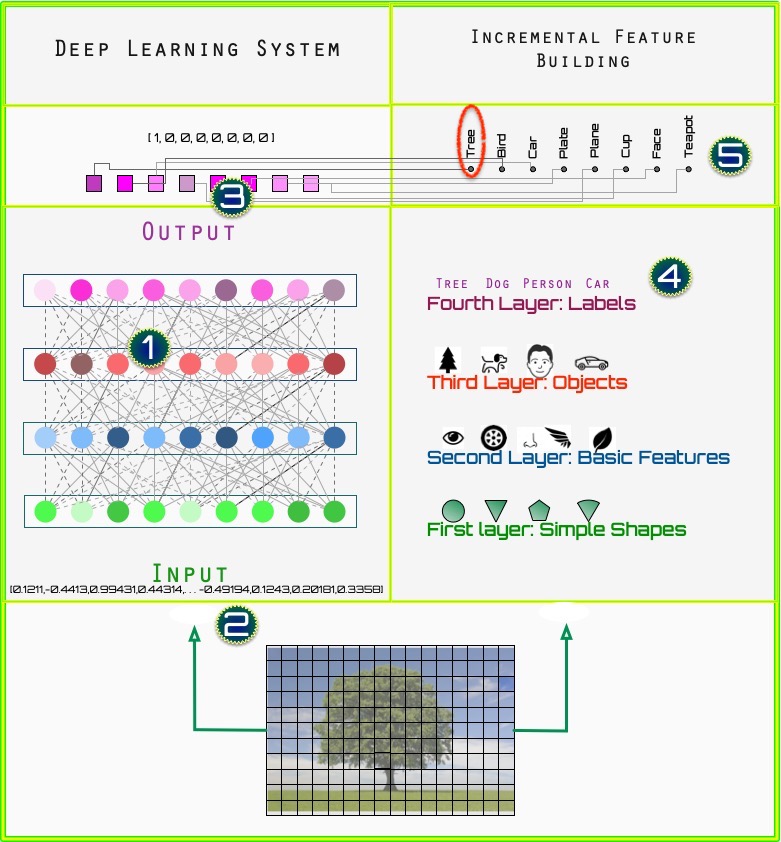
Figure A
In Figure A, [1] are four layers (the rectangular slabs) of simple processing units, from input ([2] at the bottom) to output ([3] at the top). Of course, a real deep learning system has many more simple processing units (the colored circles) than depicted.
The lines from each circular unit to the next depict how information is conveyed from one layer to the next, and where knowledge, or rules, are stored.
Both input and outputs are encoded as vectors, which are also depicted ([2], [3], [5]).
Identifying an Image of a Tree
In the example shown, we quantize a picture of a tree, and convert each square into a real value corresponding to its red-green-blue value. This is translated into an input vector representing the image of a tree.The output is represented as the known label of the object, in this case a tree ([3,5] at the top). This again is represented as a vector, with each element corresponding to one possible label, including the correct one in this case.
The right side of the diagram ([4] and [5]) offers insight into how the deep learner organizes information as it learns, although, for explanatory purposes, it is an oversimplification .
In [4], the first layer learns or discovers simple shapes like lines, curves, rectangles, and circles. The second layer puts those together to learn more complicated features like eyes, tires, wheels, handles, and so forth—parts of more complex objects. The next layer learns to combine those into complete objects such as trees, faces, and vehicles. The final layer (at [5]) learns to assign labels to those objects.
Probing a Hidden Layer Imagine that we skip the input and just probe one of the hidden layers directly. By this we mean we set the hidden, internal processing units (one of the layers seen at Figure A[1]) to some set of reasonable values. If we probe that hidden space, as shown in Figure B, one of those points results in an output that corresponds to, for example, “tree,” another to, for example, “truck” and so forth.
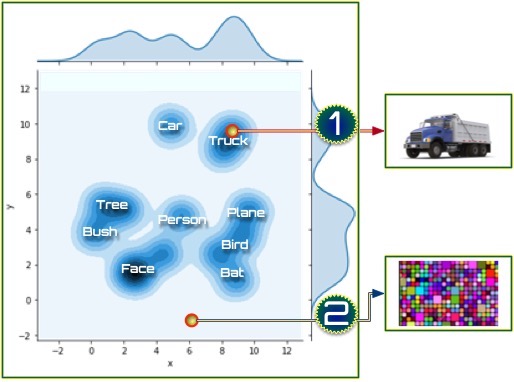
Figure B
There are many empty or light blue patches in the hidden space. This is because there is nothing in our learning algorithm that forces items to use the hidden space efficiently or to cause items to cluster together. Vast portions of our hidden space map to meaningless outputs. Only the dark blue parts of the hidden space map to well-formed outputs.
Thus, the darker blue parts of the figure represent parts of the hidden space that map to legal, well-formed object in the output— that is, real objects. The pale areas represent parts of the space that don't map to anything well-formed in the output space—that is, noise.
This is significant if we are planning to use our deep learning system as a content generator, and here's why: one of the first principles of a content generation system is that we can have a hidden space like this and probe around adjacent areas to generate new content.
To think of this in terms of genes, the dark blue portions of the space correspond to genes that render viable creatures, while the pale areas correspond to lethal gene sequences that don't create viable organisms. To return to our problem space, in terms of deep learners, a “viable organism” is an output that is well-formed.
What Is Well-Formedness
If our deep learner has been trained on documents, well-formedeness means that the generated document makes sense both grammatically, semantically, and topically. It falls within the topic space of the documents that the deep learner has been trained upon. This means that if we have trained it upon a large set of short weather reports, it should produce, ideally, a new well-formed, grammtically correct weather report, not a recipe or random sentences.
As a second example, if our learning system has been trained on images, as in Figure A, then probing the space should provide a new image that is a complicated but reasonable admixture of all of the images it has been trained upon, unless we probe at some point directly in the space where an actual learned item is. The deep learner produces an object that makes sense to us as a real-world object, recognizable to us as a close relative to one of the objects in the training set, even if it is not one of the actual objects presented to the deep learner during training. See, for example, Deep Dream.
Finding Well-Formedness
The difficulty, as you can see in Figure B, is that after training, many parts of the hidden space are empty—that is, they don't correspond to any sort of well-formed real world object. Thus, probing that part of the hidden space results in an output that is essentially hash or noise.Figure B is, of necessesity, a simplified diagram, in only two dimensions. It is easy for us to look down on it and see where the dark blue patches are. The reality is the hidden space can be hundreds or even thousands of dimensions in size, meaning that finding the dark blue areas is often an intractible problem. What we would like, ideally, is for the dark blue area is to be a small, continuous area near the center of the space. We would also like for similar items to tend to be near each other, as with a self-organizing map.
To get back to our point above, if we are planning to use our deep learning system as a content generator, we would like a techqniue that shapes the space such that probing around a small central area of it permits us to generate new exemplars without having to worry about vast empty areas. Such a techqniue would tend to push all the dark blue areas into a single cluster in the center of the space.
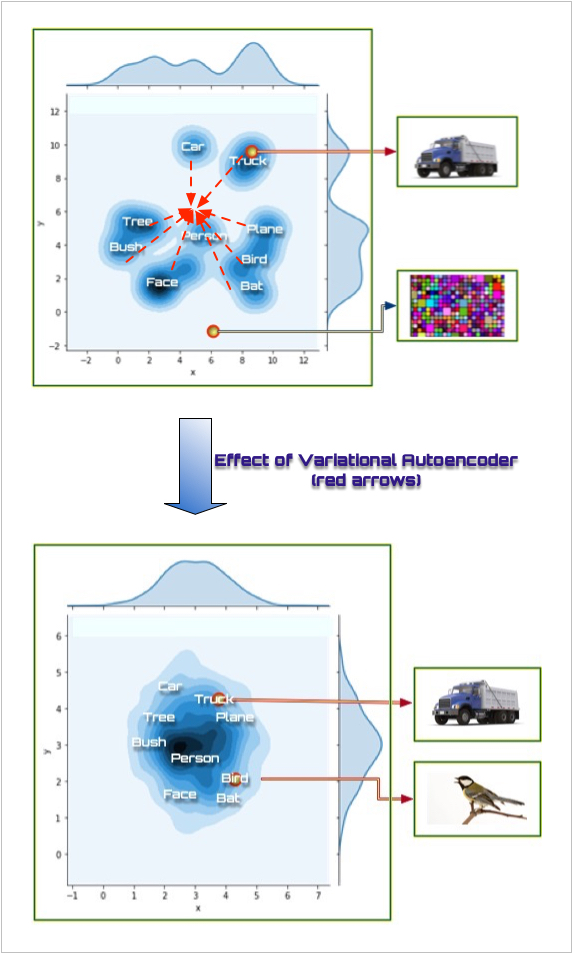
Figure C
Variational Auto-Encoder
One technique for overcoming this problem, and with which we have had initial success, is the variational auto-encoder (VAE). The VAE tends to push representations in the hidden space into the middle of the space, as seen in Figure C.
This tends to force all legitimate or legal representations to be somewhere within the middle of the hidden space, meaning that as long as we probe within the center of the hidden space (for example, all hidden unit values are set to small values close to zero) then the resultant output should tend to be well-formed.
Content Generation and Personalization:
Origins in Web Search and Targeting
The advent of web search in the late 1990s unleashed a mad scramble to evolve the best recipes for extracting money from search. Most websites at the time made money via banner ads, those annoying and usually irrelevant ads for shaving products and pet food at the top of the page. They were for the most part not specific as to whom they were displayed to, essentially being shown in random rotation until the paid for number of impressions had run out. This strategy was not going to financially support the entire industry.
One answer was “targeting.” Targeting is a rarefied extension of the marketing segmentation done in publishing and media buying for years, where publishers and broadcasters promised that some percentage of their market, translating into so many thousands of readers or listeners or viewers, were, for example, men between the ages of 35-44 who drank at least three times a week.
Targeting has been a key issue in the growth of the internet and the web in the past twenty years, and a key part of the struggle of web sites to figure out how to make money. Originally web sites had little feedback information about users, what we call today “tracking data,” and had at best about as much demographic information about users as magazines did about their readership.
The accumulation of years of data at companies such as Google, Yahoo, and Facebook converged upon on-line targeting as a major component of the solution. In targeting, a variety of algorithmic techniques are used to match specific advertisements to specific individuals or clusters of individuals. Specific identifying characteristics, or input, are mapped to specific demographic characteristics, or output. Given the vast amount of information internet companies collected over the years, a nearly infinite trove of fine-grained information was amassed to be fed to these algorithms. A study even suggested that so much information was revealed online that an individual’s sexual orientation could be accurately predicted by their social links.
Shoshana Zuboff refers to the incidental footprints we leave as we make our way across the internet as “digital exhaust.” What was initially thought of as a waste product hidden away in trillions of bytes of log data later came to be the foundation of a multibillion dollar industry. The massive individual data collected permitted targeting at a level heretofore impossible. Zuboff discusses the level of granularity and the power that such information leverages.
But this new on-line, digital, algorithmically-driven processed promised much more fine-grained targeting, with individuals who have, for example, expressed an interest in "Band X" within the last thirty days, or who have met at least three of twelve criteria for purchasing a first-time house within the last sixty days.
These tags, in turn, can become the building blocks for higher-level behaviors, such as serving ads for bands similar to "Band X" to Facebook users who have expressed an interest in Band X, or serving ads for home loans or home-furnishing ensembles for those who have met house-purchasing criteria. This more focussed algorithmic approach obviously yields better results than the simpler marketing segment approach used in the pre-internet era.
From Broadcasting to Narrowcasting
Technological developments in media have historically been in the direction of making information more generally available: smoke signals, Gutenburg’s printing press, the telegraph, railroads (in the sense that the people carried by trains also carry information to their destination), the telephone, radio, the car (see railroads, above), TV, communications satellites, the internet.
The Curse of Dimensionality
All of these broadcasters or amplifiers paradoxically contain within themselves the seeds of their own undoing. The more information that there is available, the more difficult it is for us to locate information that we want. This is “the curse of abundance,”’ or, to borrow from the nomenclature of statistics, the curse of dimensionality: the more distractors there are, the harder it is to find our target.Long past are the days when one person could have at least a nodding familiarity with all areas of human knowledge (Goethe, some have claimed, was the last figure to do so, and he died nearly two centuries ago). Today, every second, more information is generated than a single human could consume in a lifetime, even Herr Goethe.
It is only with the advent of high-speed computers and the proper algorithms to run on them that we have been able to begin to balance the human advancement of broadcasting with the concomitant, complimentary advancement of narrowcasting: finding ways to narrow down our selection to the targets we desire as our overall set of choices or distractors grows greater.
Thus, it is possible to target a particular group of Facebook users as being more likely to be potential consumers for, say, a particular concert.
Targeting, in this context, can have several meanings. As a user, it is locating that information and only that information we are looking for. As a piece of information (or, more accurately, as an entity with an interest in pushing a particular piece of information to an individual to whom it is relevant), it is users, Facebook users, Google searchers, and the like, and not information, who are the targets. But in both cases the underlying mechanics are similar: we have a vast space of users and of content seeking each other.
The past twenty years have seen the explosion of technology designed to tip the scales back in the direction of narrowcasting. Many of these technologies use so-called “digital exhaust” to create extremely detailed profiles at the individual user level, and then use sophisticated AI algorithms to match users to target information, such as an advertisement for a musical event (e.g., "Coachella 2020"). We are able to eliminate a large number of the distractors and boost the ratio of targets in our search space.
Targeting Inputs and Outputs
Inputs to a targeting system could be essentially anything recordable through interaction with the internet: interests that the person had expressed on their webpage, social links, things that the person had discussed in blog posts, or even particular ways in which they expressed themselves linguistically (do they prefer slang and contractions or do they spell things out and use full sentences?).
Outputs, too could be almost any sort of overt human behavior that could be connected with online. Thus, an output could be as general as “about to buy a car” (send them car ads) “have a baby” (send them diaper ads) or as specific as “going to an EDC concert next week” (send them local lodging ads).
Note that these are almost always probabilistic, not deterministic, links. Every bit of information , no matter how seemingly insignificant on its own, suggests but does not determine an outcome. But as these small pieces of information accrete they can contribute to a broad and highly predictive picture of behavior.
This notion of collecting data for personalization at the individual level, which is really what targeting is, will become important later when we examine what some of the algorithms we hope to develop do. For example, imagine, say a news magazine article being targeted, and someone this is further true the article itself is the same article no matter what target is pushed to.
No personalization is involved in the sense that we don’t need to necessarily integrate actual individuals at the time that our algorithms are operating, merely that our algorithms must have built into them knowledge of different kinds of target so that they they can prepare various versions of the same document. It is only at the time that a particular instantiation of a document is rendered from the base “quantum document” that personal information about the target is possibly required.
Targeting and the technologies behind it are relevant to our current endeavor because an important component of what we want our algorithms to perform is personalization. When we edit existing content and try to improve it with respect to a target or when we generate new content, if we are personalizing it then we are targeting it. We expect many of the same issues that have come up with targeting in our previous work will come up here as well. Thus many of our discussions of this project will address the targeting aspect as appropriate.
Key Points
- • The internet has overloaded us with data. Our ability to find what we need, and to respond,must be orders of magnitude faster.
- • Leviathan is a response to this: a cooperative project to bring the best deep-learning natural language processing algorithms into common use.
- • Intellectual property protection: Leviathan allows creators to expose as much or as little of their algorithm as they choose.
- • Our goal is to help today’s users, but also to observe how tools are used so that we can build better for future users.
- • Improvement comes by making each developer's contribution a simple experiment