What advantage will Artificial Intelligence provide the writer, the editor, and all others involved in content creation? We focus in this section on these end users, and not how knowledge engineers marshal their training data or how their algorithms come to learn.
With respect to our discussion in the introduction, the GUI/dashboard is the watering hole at which algorithms and user tools meet to be tested. Here we can implement algorithms in vitro, see how and if they are used, and conserve those which are.
Research reports demonstrate how well these algorithms function in a theoretical context. Our interest is in how well they work in a real-world production system. That is the goal of our project, an ongoing set of tools to explore current NLP / deep learning algorithms and their interaction in ecologically vaild tasks.
Our graphical user interface (GUI) dashboard is the visible surface for a variety of deep learning, natural language algorithms that are accessed via JSON. What will it look like and what functions will it perform?
We offer one version, what we term “Reference Platform Alpha,” below.
Reference Platform Alpha
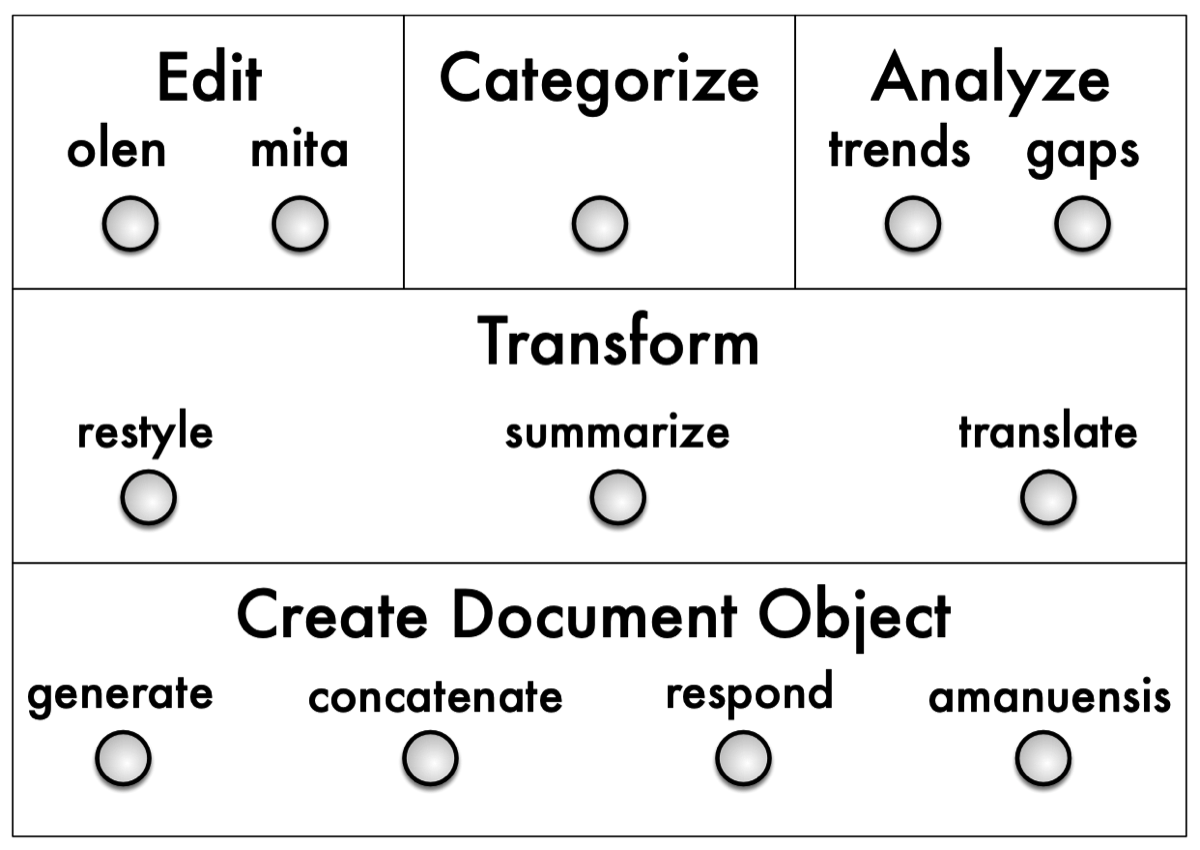
Leviathan creates a platform with potential use cases including:- evaluating the appropriateness of a document for a target audience (categorize).
- evaluating sub-sections of a document for a target audience (categorize).
- providing sentence-level suggestions for a document to make it hew closer to a target audience (edit).
- given targeting input, generate a document framework or outline that satisfies both semantic and target constraints (e.g., a New Yorker style movie review of Avengers: Endgame) (restyle).
- given targeting input, generate a full document framework that satisfies both semantic and target constraints—e.g., write an article (generate).
- translate a document from one language to another (translate).
- work collaboratively with an algorithm or set of algorithms to build or edit a document (amanuensis).
- create a framework or outline for a document (generate).
- analyze a topic space and provide a summary of what is being talked about in that space and what kinds of reporting are missing (analyze).
- respond to a document, such as a post (respond).
- create a document from a seed or key (generate).
- take a group of loose notes and produce a finished document (concatenate).
Summarize
Input Panel

Function Select
Parameters Select
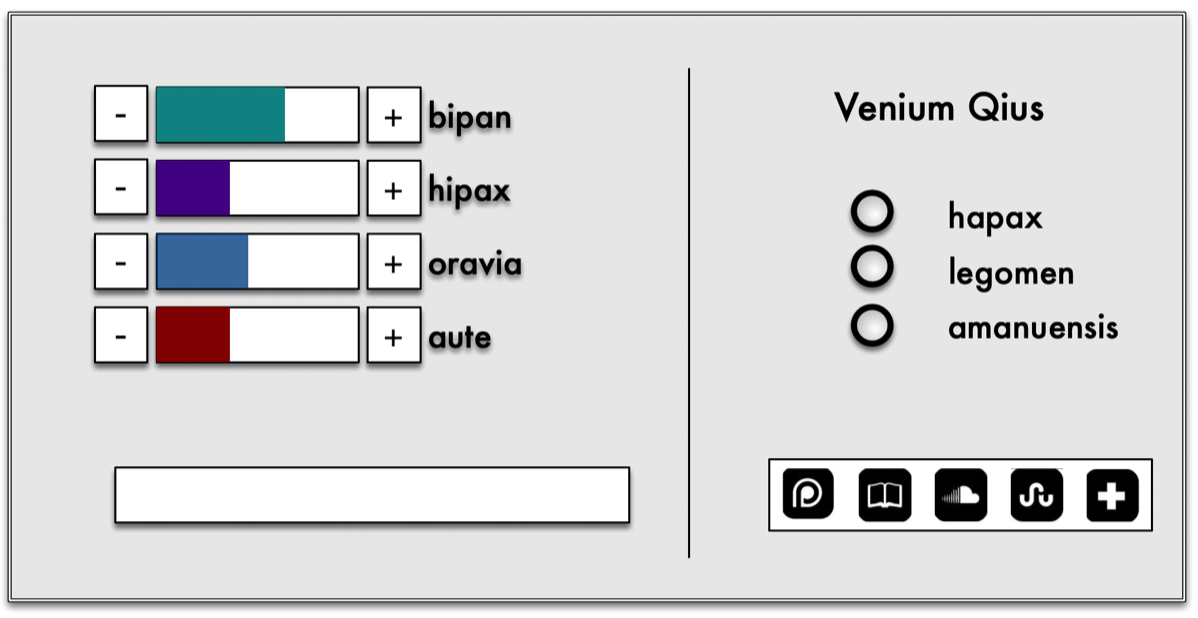
Output Panel

The Dashboard
The dashboard has four major parts:
- A window for the actual text or group of texts.
- A window to select the function (for example, edit or summarize).
- A window to provide parameter input to the algorithm, based upon the function selected, via radio buttons, menus, input boxes, and so forth.
- A window for the algorithm's output.
We assume two work modes for our dashboard: multiple document input, and single document input. In multiple document input mode, we select a group of documents as our starting point. In single document input mode, we work at a more fine-grained level with a single document. “Multiple document input mode” is more akin to a traditional tool. Filtering can be set using the second pane of the dashboard (input to the algorithm) with, for example, radio buttons. For example, if we have a deep-learning-trained filter such as “New Yorker-ness:rdquo;, that predicts the likelihood that a document is from The New Yorker, we can return all documents in a set that resembleThe New Yorker above a set threshold.
Multiple document input mode is more likely to be used in the context of content selection, categorization, and evaluation than content generation. However, we can imagine a use case where a group of documents are selected and then transformed. For example, find all documents that match the semantics of “Wired movie reviews” and transform them into summaries.
Conversely, “single document mode” is more focussed on content generation. While we discuss the many issues involved in content generation here, one issue is starting point: are we starting from:
- a blank page (genuine content creation from nothing, of the “Let there be light...” type) where the only input is something of the form of“write me 2,000 words about acid rain.”, or
- some pre-exisiting text, that we intend to set about transforming: translating, augmenting, summarizing, and so forth.
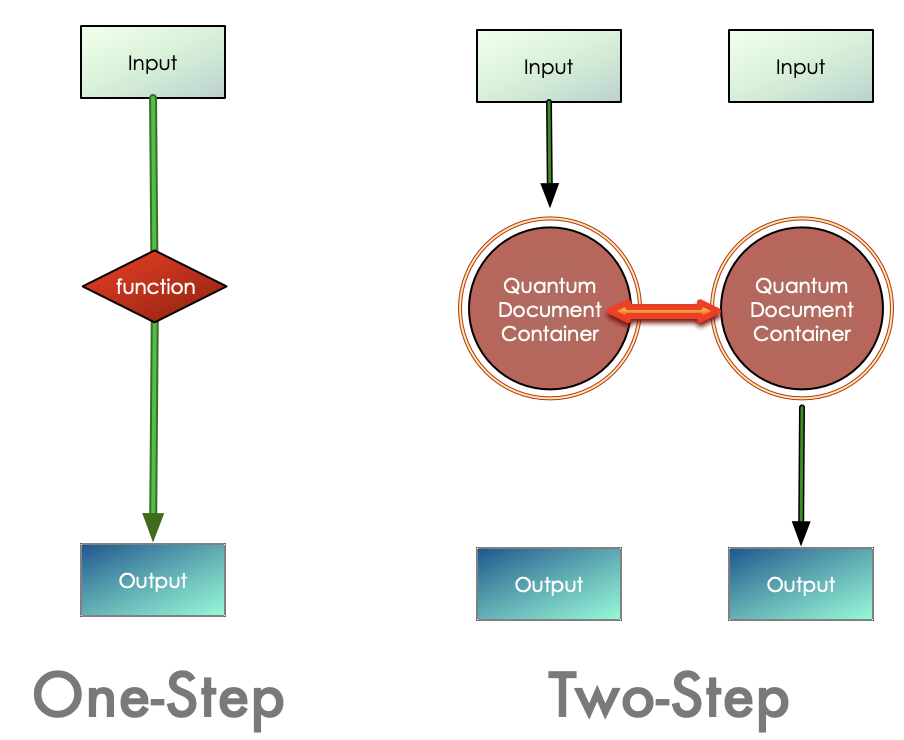
Our model of content transformation and content creation is not one-step: that is, an input being transformed into an output. Rather, we use a two-step process: the result of a transformation is stored in a container. A different function then reads out the contents of the container.
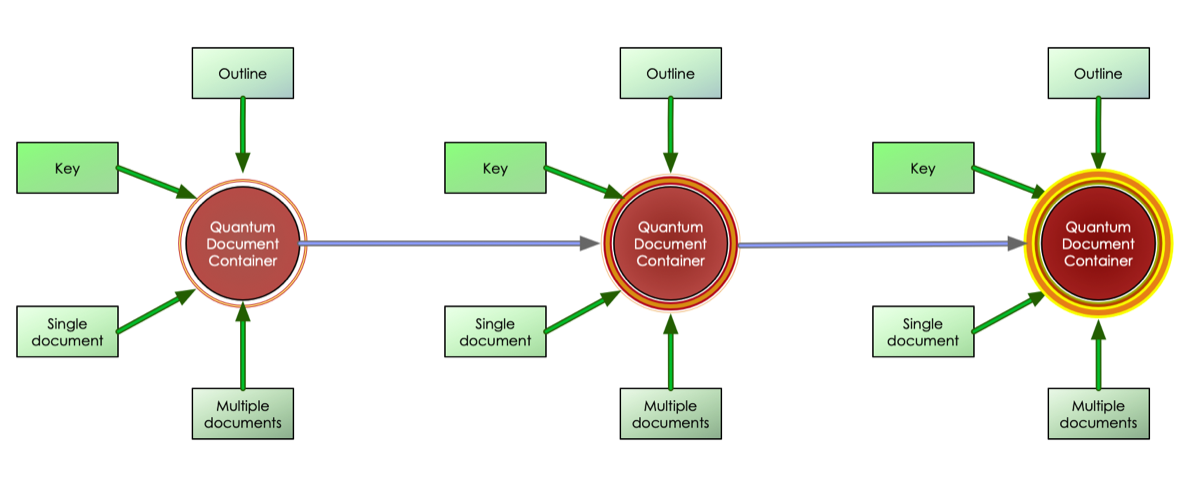
The Quantum Document Container stores all information proveded to it, rather like a genome or a blockchain. Any algorithm that uses information from this container ignores information with unfamiliar tags, so there is essentially no such thing as an “error condition.”
The diagram below depicts a schematic view of the container accumulating information over a series of three passes. The container is not directly read or interrogated by human readers but is interpreted by an additional personalization layer that outputs to a human readable stream.
Sending JSON to the Algorithm
To the right is one possible simple encoding of a text document from the front end.

Returning JSON from the Algorithm



